
ChatGPTをさらに快適に使いこなしたい方へ。
こちらの記事ではAIでより効率的に成果を生み出せるように「ChatGPTに追加学習させる方法」についてまとめています。
今回はChatGPTに学習させる方法として、ファインチューニングの手順や注意点にフォーカスして解説。
とはいえ公開されたばかりのChatGPT、本格的なパーソナライズ化にはまだまだ限界があります。将来的に改善される取り組みについても触れながらご紹介していきます。
Contents
ChatGPTの仕組み

ChatGPTの学習に触れる前に仕組みを理解を深めることが、ChatGPTの利用にあたり重要です。そもそも「ChatGPTってどんなロジックで動いているの?」を知らないと学習について理解が深まらないからです。
結論から言うとChatGPTとは、簡単にいえばWeb上の膨大なテキストデータを解析して、入力した質問の回答を出力する仕組みです。
つまり、ネット上にある無数の情報をインプットして、質問されたらインプットした情報の中からふさわしい情報をアウトプットしてるだけです。
さらに具体的にいうと、
GPT-3を微調整したInstruct GPTというモデルがベース!
強化学習(RLHF)については、OpenAIの2022年の論文で詳しく説明されています。
GPT-3の事前学習に使われているデータセットは以下の内容です。
- Common Crawl
- WebTextデータセットの拡張版
- インターネットベースの図書コーパス
- 英語版wikipedia
ChatGPTになるまでの過程
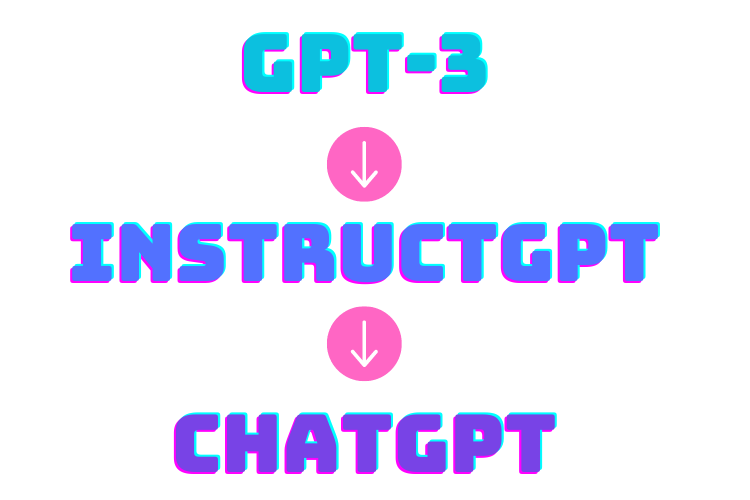
ChatGPTの仕組みを深掘りしていくと、モデルの進化が見られます。
こちらは、モデルの特性と進化の過程を表した一覧です。
| モデル | 特性 | 進化の過程 |
|---|---|---|
| GPT-3 | 自然な文書生成 | アラインメント問題 |
| InstructGPT | 人間のフィードバック | 対話特化 |
| ChatGPT | 対話に特化したより自然な文書生成 | ー |
現在のChatGPTのベースとなるGPT-3の誕生により、自然な文書生成ができるようになりますが、アラインメント問題が生じます。
アラインメント問題とは
GPT-3が不正確な内容、または非道徳的な文を出してしまうという問題のこと。
GPT-3による生成文が人間の好みとalign(一致)していないことを指します。
この問題を解決するために登場したRLHFでファインチューニングをおこない、InstructGPTへと進化を遂げることに。
さらにこれを対話特化させることで、いまの高性能なChatGPTへと至るのです。
- 入力文に続く文を予測するモデル
- TransformerにおけるDecoderで構成される言語モデル
- 言語モデルの利点:教師なし学習
- 人間のフィードバックをもとに学習させる
- RLHF(=Reinforcement Learning from Human Feedback) という手法で実現
学習ステップは以下の過程を繰り返すことで反映されます。
- 教師あり学習モデル(SFT)
- リワードモデル(報酬)
- 強化学習モデル(RLHF)
ChatGPTはInstructGPTと類似。違いは以下の2つ。
- モデル:GPT-3.5
- データ:会話データ
InstructGPTにおいては
「プロンプトと出力」
対して、ChatGPTにおいては
「対話に特化している」という点が特徴です。
ChatGPTに学習させる方法は3つ

せっかくなので、「学習させる方法」についてChatGPTに聞いてみました。
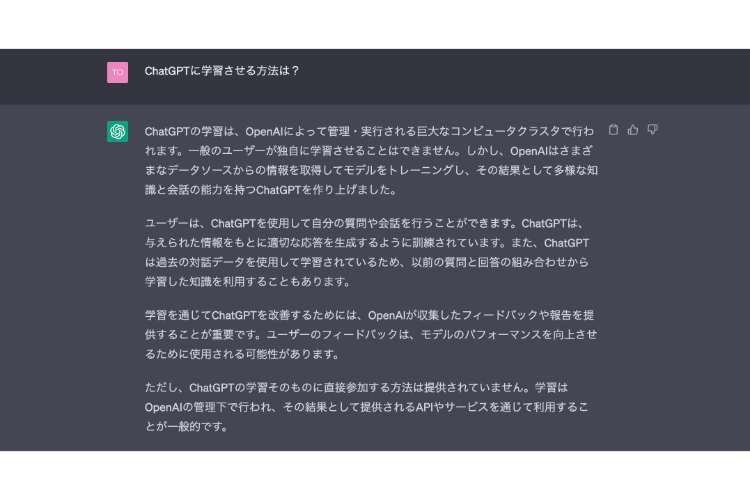
「一般ユーザーが独自に学習させることはできません」といった答えが出力されました。
機械学習の訓練は、あくまでOpenAIが管理しているものであるという内容。
ただし、APIサービスの利用を通して学習させることができるようなことも最後に付け加えてありますね。
それでは、質問を少し変えて「ChatGPTで効率的に成果を生み出せる使い方」について聞いてみました。
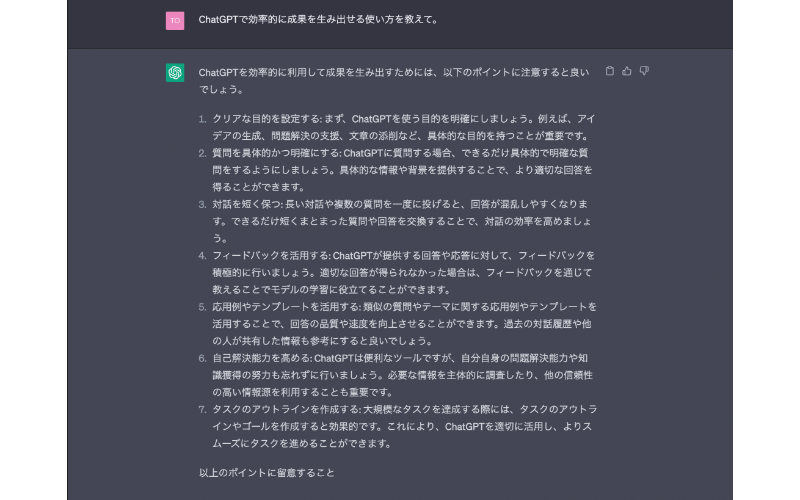
ChatGPTの解答は、以下のポイントに留意して活用することだという内容でした。
- クリアな目的を設定する
- 質問を具体的かつ明確にする
- 対話を短く保つ
- フィードバックを活用する
- 応用例やテンプレートを活用する
- 自己解決能力を高める
- タスクのアウトラインを作成する
以上を踏まえて「ChatGPTに学習させる方法」を調査した結果、以下の3つの方法をご紹介します。
- 学習段階からデータに入れておく
- プロンプトに学習データを入力する
- ファインチューニングする
ChatGPTのAPIについても気になる方は>>ChatGPTのAPI について解説!をご覧ください。
学習段階からデータに入れておく
ChatGPTへ独自に追加学習させる方法1つ目は、学習段階からデータに入れておく方法。
まずは、あらかじめVectoreStoreに利用したい独自データを学習モデルとして登録しておきます。
検索時にはLangchainというライブラリで、ユーザーからの質問に該当する情報を独自データベースから抽出し、ChatGPTによって回答させるといった仕組みです。
ChatGPTに全てのデータは渡せないため、独自データをVectorStoreというデータベースに保管する必要があります。
プロンプトに学習データを入力する
2つ目は、プロンプトへ学習データを入力する方法です。
ユーザーの入力に対し、それに関連するデータがあれば該当箇所の文章を抜き出してプロンプトに入れ、その情報に基づく回答をするようにします。
そのため関連情報を抜粋して、プロンプトへ入力する必要があります。
LlamaIndexやLangChainの関数を利用することで簡単に抽出が可能です。
ファインチューニングする
3つ目はファインチューニングすることです。
ChatGPTは事前学習済みの状態を初期値とし、特定タスクの適応を目的としたファインチューニングを実施しています。
ファインチューニングを行うには、対象とするタスクに応じたデータセットを用意します。
ファインチューニングの手順

ファインチューニングの手順は以下の通りです。
- ライブラリをインストール
- テキストデータを用意、事前学習済みモデルを読み込む
- モデルが理解する形式へテキストデータを前処理
- モデルをファインチューニング
- ファインチューニングしたモデルを保存
ファインチューニングの注意点
ファインチューニング実施にあたっての注意すべきポイントは以下の3つです。
- データの量・質
- モデル選択
- ハイパーパラメータ調整
用意するべきテキストデータは、以下の要件でモデルの性能が向上すると考えられています。
- データ量が多いのが好ましい
- データの質が高いほどいい
事前学習に用いたものと同じタスクに向いているものが、ファインチューニングに好ましいモデルとされています。
ファインチューニングで用いるハイパーパラメータ(学習率・バッチサイズ)の調整により、モデル性能の向上が見込めます。
ChatGPTをパーソナライズ化
ChatGPTのファインチューニングによって、ある程度の範囲でパーソナライズ化が可能です。
具体的には、ユーザーが所持するデータベースに応じ、ChatGPTがその学習データを取り込んで特定のコンテキストに適応させて文書生成するように調整することです。
本格的なパーソナライズ化は限界がある
主に3つの理由から、この課題を解決するのは困難と言われています。
OpenAIはChatGPTの限界について、次のように示しています。
- 強化学習おいて、現時点で信頼できる情報源(Ground Truthの取得元)がない
- 解答の正確性を突き詰めて学習させれば、正しく答えられる質問に対しても解答不可と判断されるケースが増加
- 教師あり学習は、モデルを誤った方向に導く可能性
人間の評価を使う「教師あり学習」の場合、モデルは必然的に人間の模倣をするようになり、以下の可能性が懸念されます。
| ケース | 懸念されるモデルの反応 |
|---|---|
| 人間の方が知識が多い場合 | 知ったかぶりする可能性 |
| モデルの方が知識が多い場合 | 知っているのに知らないふりをする可能性 |
将来的に改善される取り組み

ChatGPTを実際に使ってみた。メールアドレスやパスワード、名前、電話番号、認証コードを登録すると準備完了。いくつか質問したら、もっともらしい理路整然とした回答が即座に返ってきたが、不正確な内容も多い。データ整理としてはアリかもしれないけど、そのままでは使えないなというのが実感だ。
— IKEZOE_Noriaki (@ookaminami) April 25, 2023
現在、OpenAI社ではChatGPTの性能向上に向けさまざまな研究が進められています。
そのなかで最も注目を浴びている、大規模な事前学習と効率的なモデルアーキテクチャーの開発。
さかのぼれば、2020年に今のChatGPTの基盤とも言われる「GPT-3」新モデルが発表。その性能は人間レベルに匹敵する文章生成能力を持つことが示された後、さらに「GPT-3.5」という最新の自然言語処理技術が採用されました。
GPT-3.5は、約13億個のパラメータで構成。これによって、かつてのAIチャットボットとは違う人間のような自然な文章生成や対話を可能に。
またOpenAI社はさらに高度な技術開発として、GPT-3の次世代版となる「DALL·E」「CLIP」モデルを発表し話題となりました。
- DALL·E:文章の説明から画像を自動生成するモデル
- CLIP:画像・文章の特徴量を共通の空間に埋め込むモデル
そして2023年3月14日に公開された「GPT-4」は、マルチモーダル大規模言語モデルです。
「GPT-4はGPT-3.5よりも遥かに創造的かつ信頼性が高く、より細かな指示に対応でき、25000語以上のテキストを同時に読み取ることが可能」と紹介されています。
こういった取り組みを遂げてきたChatGPTの進化は今後も止むことなく、より高度な自然言語処理タスクに対応するであろうと期待されています。
まとめ
ChatGPTは、ユーザー側でのファインチューニングで個人のニーズに合ったカスタマイズも可能であることがわかりました。
人工知能の中で今もっとも注目されているChatGPTの高い性能を発揮させるために、大量のデータセットで行う事前学習。
今後さらに効率的なモデルアーキテクチャーの開発などによる性能向上が加速していくことが期待され、ChatGPTからますます目が離せません!